[深度学习邪修] Flash Attention 是怎么优化计算过程的🤔
Attention 计算存在的问题
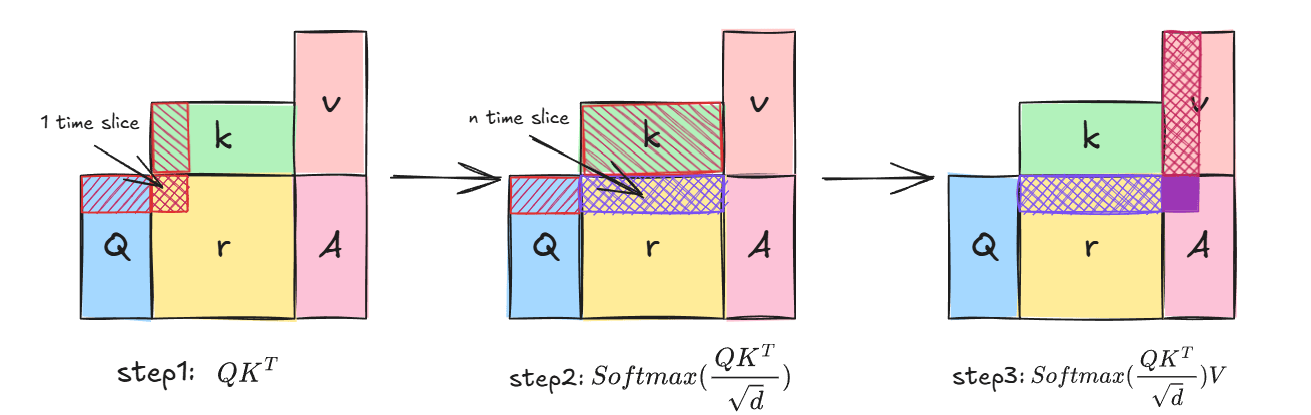
Attention的计算可以大致分为这三个步骤,首先我们必须计算,只有在被遍历一次后,得出中间变量-相似度得分矩阵的某一行,才能对该行整体作计算。事实是,即使有GPU并行能力的加持,要得到的某一行,也需要等待个时间片。
另外,计算的速度是非常快的,计算的所用时间仅仅占时间片的一小部分,但计算过程中往往伴随着频繁的开销巨大的内存访问,内存访问是高耗时操作,这带来了内存读写瓶颈
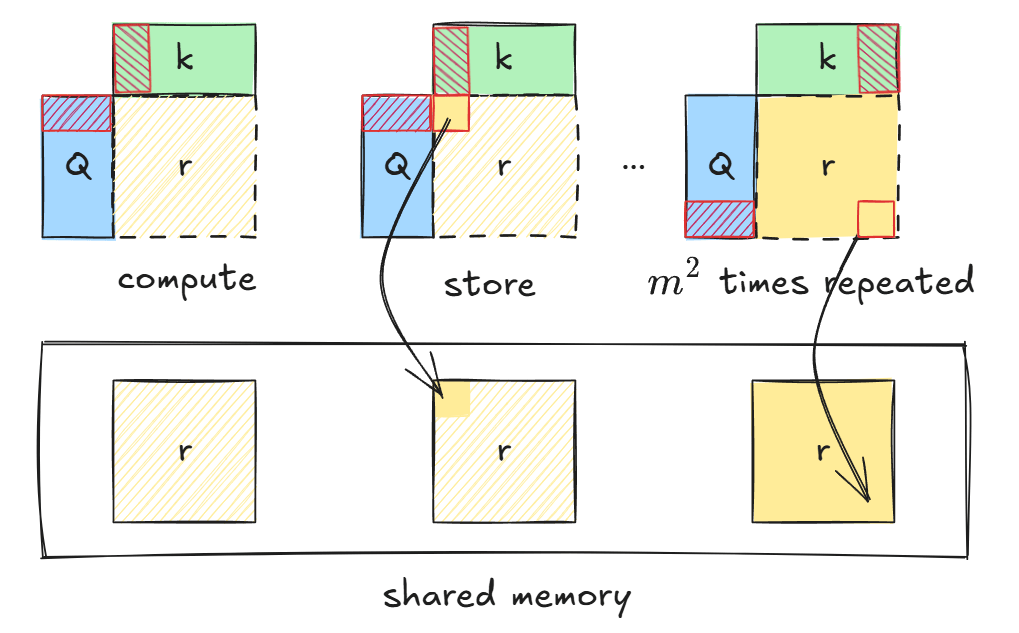
得分矩阵计算时的内存操作如上图所示,在内存分配之后的计算过程中,每一个时间片都伴随着一次存储操作,直到相似度得分矩阵的所有元素被计算完成,另外,后续计算中同样伴随着多次内存操作:
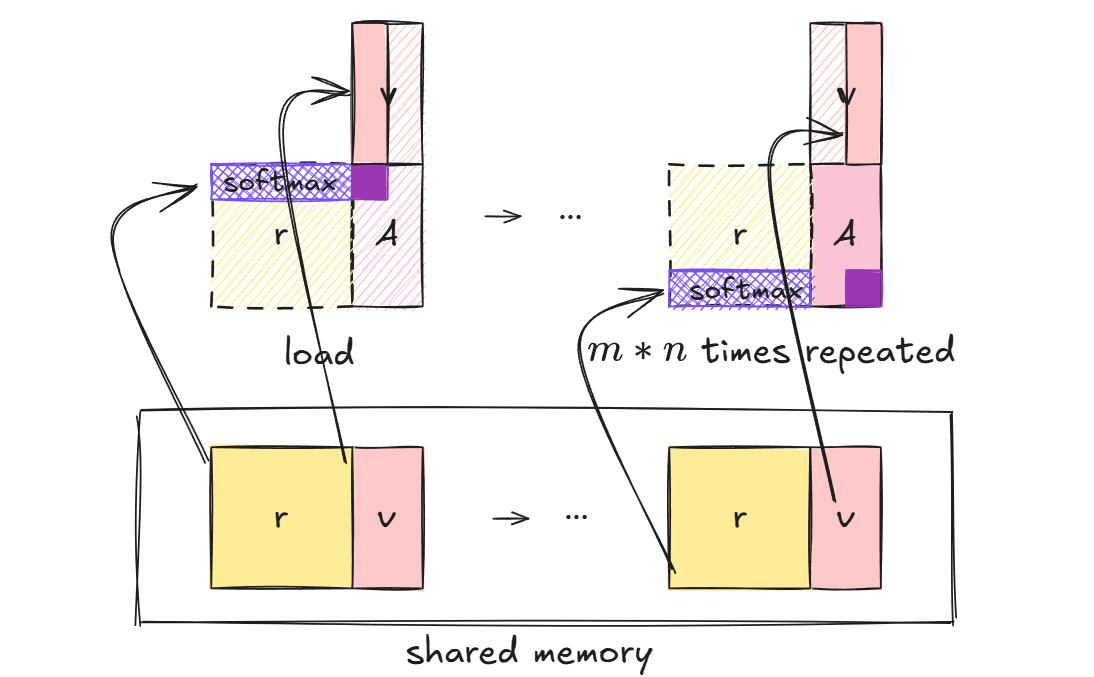
后续的SoftMax和矩阵乘法操作,每次读取相似度矩阵的一行数据,用于计算Softmax,并参与后续的矩阵乘法合并计算过程
直观上减少内存操作的方式就是不存储中间结果(相似性矩阵)到内存中,让的计算一气呵成。假设我们有某种方法使得Softmax的计算不再阻塞并行过程:
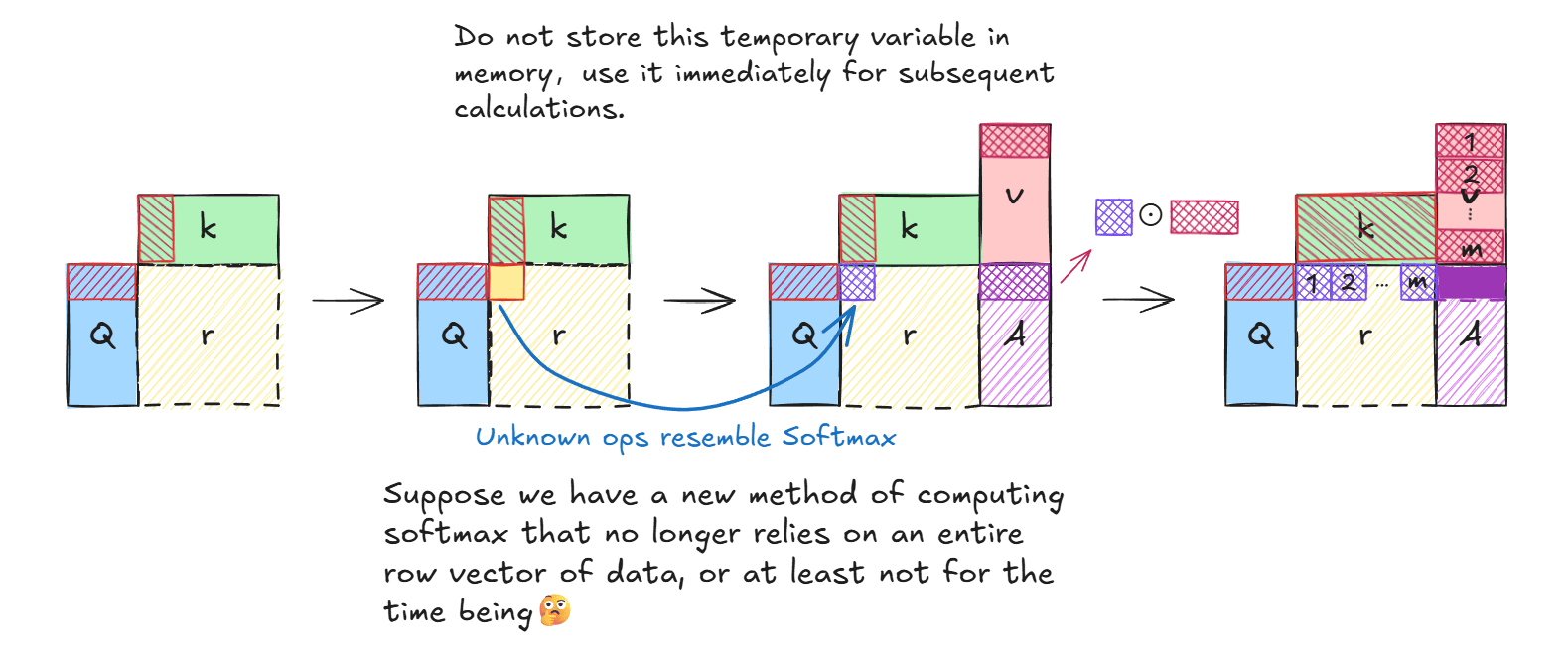
图上所示,假设有一个类似Softmax的计算,但他不依赖一整个向量的数据为了避免混淆实现与理论,先使用下图的计算过程:
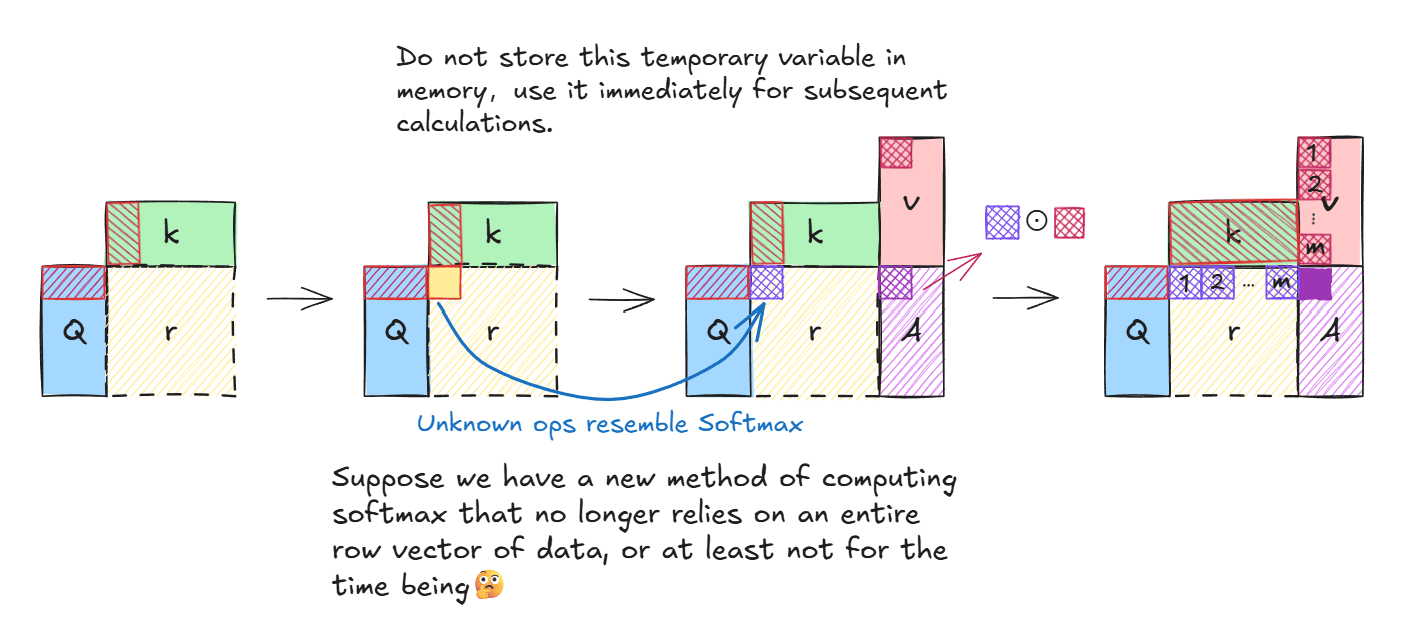
如上图所示,假设我们已经拥有了一个类似Softmax但不需要一整个行向量的运算(或者干脆排除掉Sofxmax)的操作,不会阻塞并行计算过程,则最终结果矩阵A的行向量计算公式为:
经此,分段式计算被我们合并为一个流畅的计算过程,此间不再有频繁的内存访问。注意,该计算使能的前提是我们有一个函数,该函数不会像Sofxmax那样阻塞并行计算过程。
演进Softmax
1. Safe-Softmax
如标题暗示,Softmax是一个暗含风险的操作,如果一个vector中含有极大值,那么在Sofxmax计算中很容易因为精度问题导致计算结果不准确,并且在后续的量化过程中易导致“饱和”现象发生。Safe-Softmax的改进思想很简单,将极大值从vector中减掉就好了:)
如公式所示,他在数学上依旧等价于Softmax,但在代码中却不是如此。可以遇见,想进行Safe-Softmax计算就必须要找到vector中的最大元素,这意味着需要额外遍历一次vector,算上原本就有的一次遍历求和 , 我们总共要进行两次遍历。
2.Online-Softmax
有什么方法能够将求最大值操作和求和操作压缩在一起呢?Online-Softmax提出了一种方法:
see? 上述计算过程将求和与求最大值操作合并在一个循环当中了!
公式中的对应于图片中的第步计算
现在我们只是通过一次遍历完成了最大值和求和操作,最大值用于计算Safe-Softmax,求和作为Safe-Softmax的分母。现在我们既没有计算vector中每个位置的softmax值,也没有计算之后其与value的乘积,此时有下列公式:
当时,结果矩阵中的单个元素被计算完成。
总结一下,我们为了减少内存访问,拒绝了存储中间结果-相似度矩阵,转而使用单步计算得到的单个元素进行后续计算;后续计算中,由于Softmax需要这样多个元素的向量用于计算分母,这与我们使用单个元素计算(不存储中间结果)的原则相悖,所以我们使用了算法,在单次遍历结束后就能计算出结果矩阵中的一个元素。理论上实现了少量内存访问的并行softmax计算。👍